







Procesamiento del lenguaje natural NLP - Notas de Optativa 1
La materia está enfocada a la inteligencia artificial y se presentará un componente fuerte en investigación. La idea de la Optativa es solucionar problemas y tratar de darle enfoques de calidad, como resultado de aprendizaje el trabajo se centra en desarrollar habilidades teórico prácticas, y la capacidad de poder conceptualizar los temas con calidad.
Esta publicación tiene los apuntes y notas sobre el tema Procesamiento del Lenguaje Natural en Python3 de nivel introductorio donde se presenta el siguiente temario:
El procesamiento del lenguaje como su nombre indica, procesar el lenguaje. El ingeniero debe y tiene que saber gramática, saber escribir, leer y redactar textos para hacer uso de algoritmos para la creación de herramientas dotadas de inteligencia artificial.
Índice
- Introducción a la Inteligencia Artificial
- Introducción a Python
- Bases NLP
- NLP - Pipeline
- Text Representation
- Text Clasification
- Information Extraction
- Speech recognition and synthesis
- Chatbots
- Search and Information Retrival
- Topic Modeling
- Recommender Systems for Textual Data
Para el Procesamiento del lenguaje natural hay que saber de gramática donde la idea es poder combinar el sistema de reglas con Machine Learning usando entrenamientos para hacer seguimientos. Usando reglas y patrones, árboles y semántica se trabaja bastante el tema en el lenguaje de programación Python.
Introducción a la Inteligencia Artificial
Inicios de la IA
Podemos decir que el tema comienza con un paper que introduce conceptos sobre el sistema nervioso, el funcionamiento neural y las contribuciones de Alan Turing, así como la programación computacional.
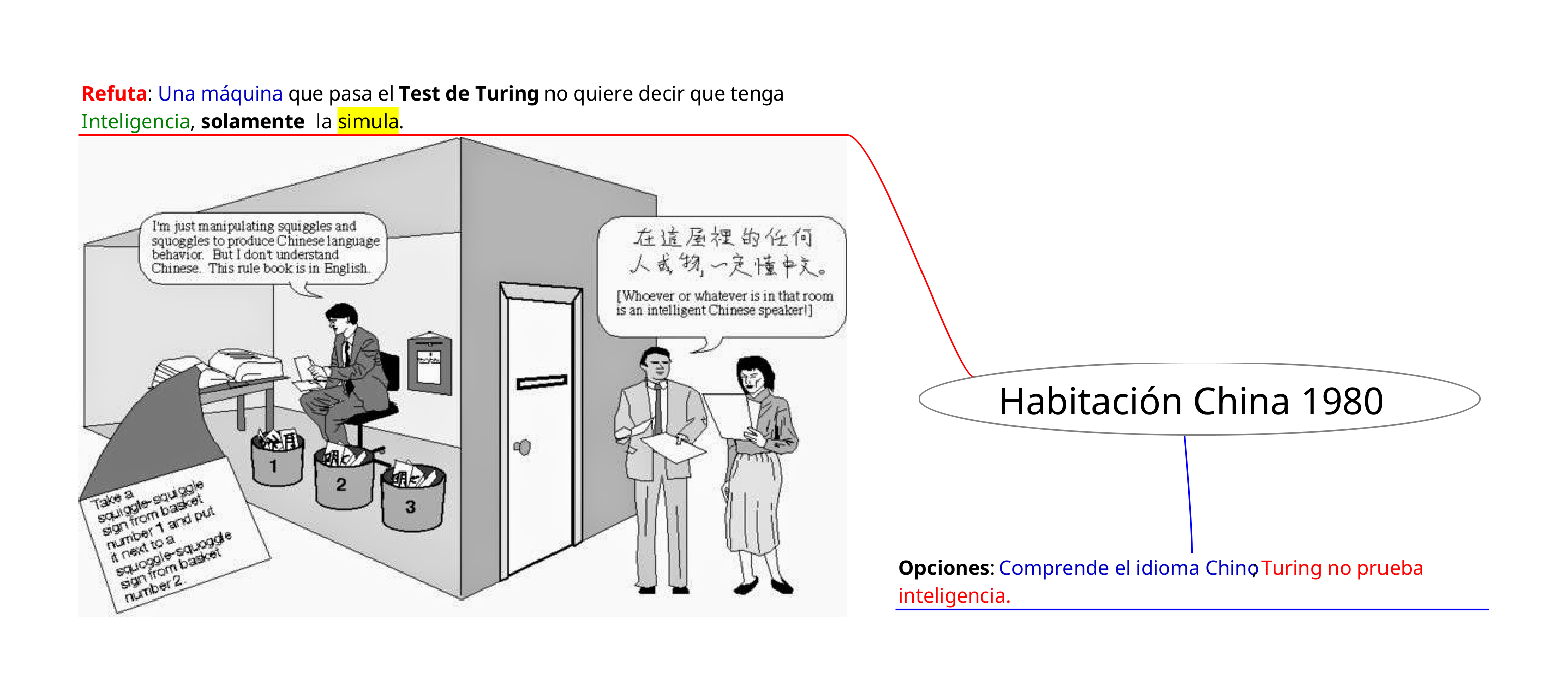
La inteligencia artificial hizo su aparición en 1943, y Alan Turing realizó contribuciones significativas con su paper “Computing Machinery and Intelligence”1. En este trabajo, Turing presentó conceptos innovadores como el aprendizaje automático, los algoritmos genéricos, el aprendizaje por refuerzo, y el famoso Test de Turing.
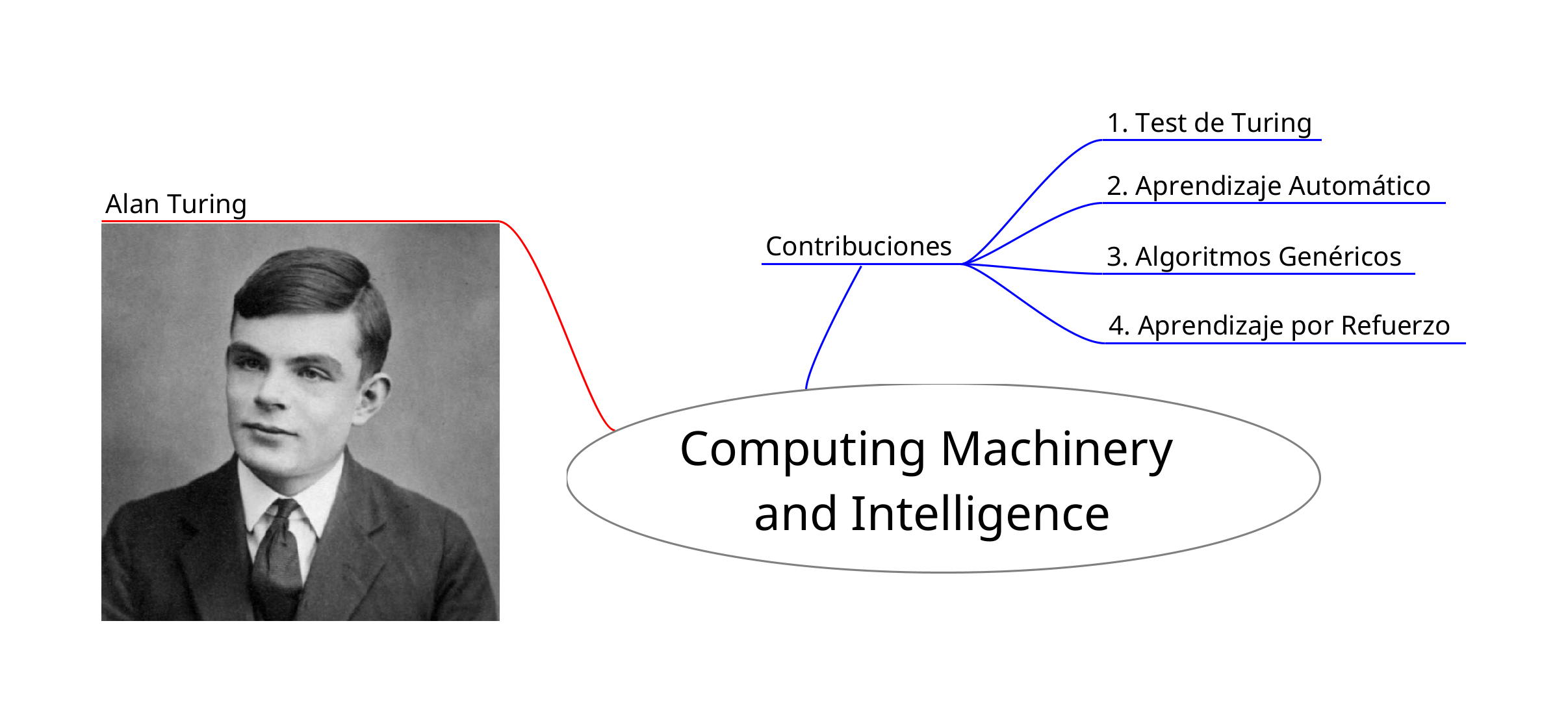
El Test de Turing involucra a dos humanos: uno formula preguntas, mientras que un humano y una máquina responden. El objetivo del test es que el entrevistador no pueda distinguir quién respondió, lo que indicaría que la inteligencia artificial ha alcanzado un grado significativo al poder engañar al entrevistador humano. Este concepto fue propuesto por Turing en 19502.
.png)
El término inteligencia artificial (IA) fue acuñado en 1956 por John McCarthy, quien definió este enfoque como “la ciencia de crear máquinas inteligentes y programas de cómputo inteligentes”. Esta idea sirvió como una forma de evaluar el progreso de los algoritmos de IA hasta ese momento3.
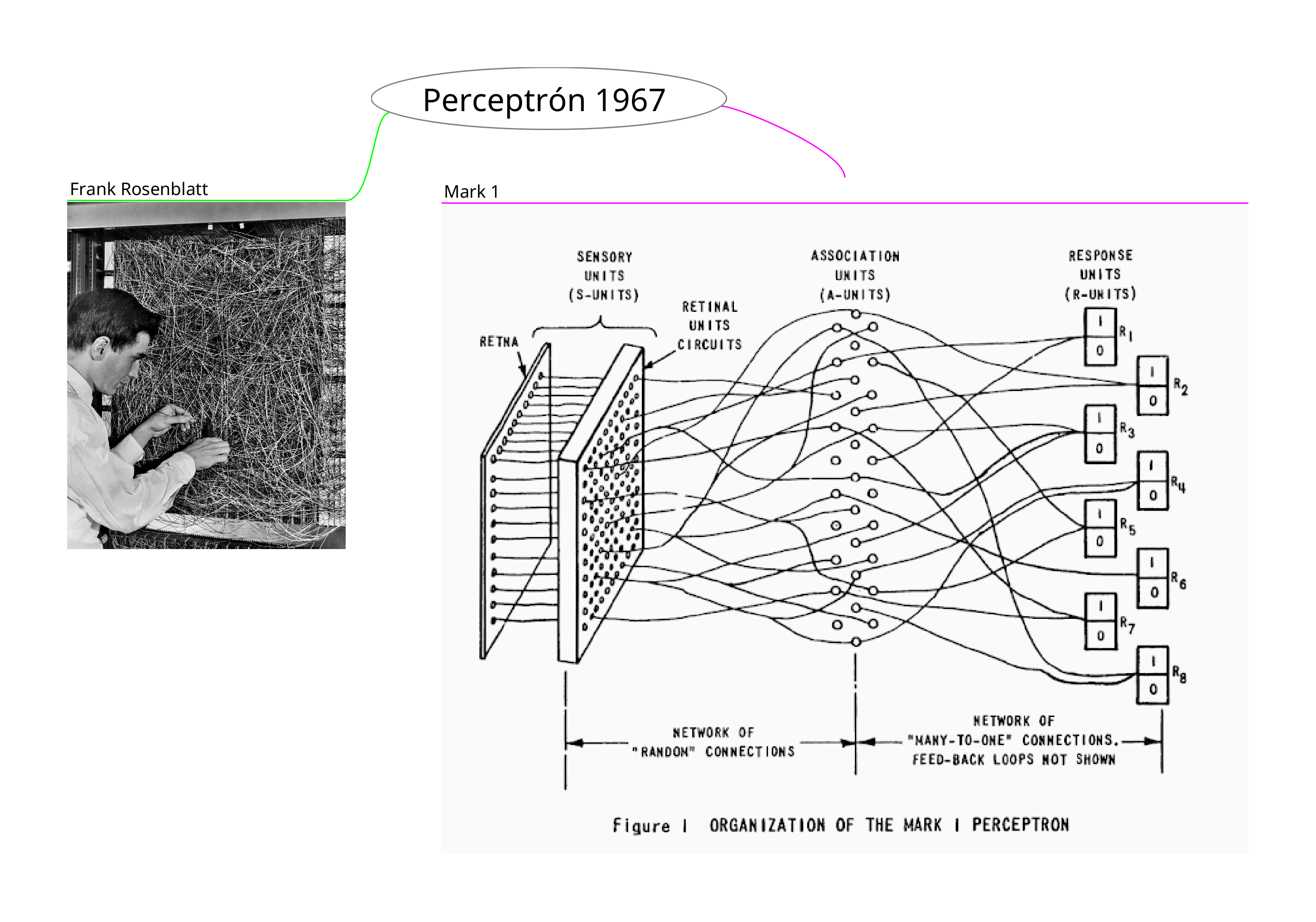
En 1967, el Perceptrón Mark 1 surgió como una implementación de redes neuronales básicas4, donde las entradas pasan por un proceso para generar una salida. Este modelo se centra en replicar aspectos de la naturaleza humana: el perceptrón recibe entradas, las procesa a través de neuronas, y con deep learning (aprendizaje profundo) la cantidad de neuronas influye en la precisión del sistema, aunque también tiene desventajas y ventajas: mayor precisión requiere más capacidad de procesamiento. Por ejemplo, procesar media página es diferente a procesar 10 páginas.
En el Deep Learning, las redes están formadas por muchas neuronas conectadas entre sí. Hoy en día, hablamos de capas de neuronas, que se comunican para dar una respuesta binaria, como 0 o 1.
En 1980, surge el concepto de la Habitación China, que es la antítesis del Test de Turing. Este argumento refuta la idea de que una máquina que pasa el Test de Turing tenga inteligencia real. Se afirma que solo simula la inteligencia, sin comprender el contenido semántico, solo el sintáctico.
Algunos Eventos importantes
- IBM (1997): Vence al campeón mundial de ajedrez.
- IBM (2011): Gana en el programa de televisión Jeopardy.
- Minwa (2015): Desarrolla sistemas de reconocimiento de imágenes superpotentes.
- 2017: Nace la base de los generadores de texto modernos, sobre los principios de generación de texto y avances hacia el futuro.

En la actualidad, los sistemas de Question Answering (QA) son una de las competencias de IA a desarrollar, junto con los generadores de texto como GPT. Estos sistemas ayudan a alimentar grandes corpus de conocimiento, que continúan aprendiendo de manera constante.
La programación funcional, con su uso intensivo de paréntesis, es extremadamente rápida y eficiente en términos de tiempo de ejecución.
: LISP
; ¡Hola,mundo!
(print "Hola, mundo!")
; Factorial de n
(defun factorial (n)
(if (= n 0) 1
(* n (factorial (- n 1)))))
Definiciones y enfoques de la IA
La Inteligencia Artificial se define como la rama de la ciencia de la computación que se encarga de automatizar conductas inteligentes. Según Luger (2005), el objetivo de la IA es desarrollar capacidades inteligentes, influenciadas por la filosofía, las matemáticas y la psicología, con un enfoque en la resolución de problemas.
- Lógica: Boole y Frege con las reglas del razonamiento.
- Complejidad: Godel y Turing con sus definiciones sobre ¿Qué es computable?
- Probabilidad: Fermat, Bernoulli y Bayes con el razonamiento de la incertidumbre.
Áreas específicas donde la IA tiene un papel fundamental incluyen la conducción autónoma de vehículos y la medición del rendimiento de sistemas.
No se limita solo a Python, la IA abarca múltiples disciplinas.
Principales enfoques de la IA
- Robots que piensan como humanos.
- Robots que actúan como humanos.
- Lógica formal y sistemas expertos, como sistemas con sensores para enviar correos electrónicos o detectar enfermedades.
- Agentes inteligentes y asistentes virtuales que actúan racionalmente.

Es importante considerar la palabra “automatización”, pero, dado que es un concepto complejo, es mejor hablar de “sistematización” para evitar confusiones.
Contribuciones desde diversas disciplinas
Estadística y probabilidad: La IA se nutre de estas áreas para hablar en términos científicos y lógicos. Neurociencia: Aporta a la IA con el estudio de las neuronas, las conexiones y cómo aprenden.

Psicología: Se conecta con la IA a través del estudio de cómo piensan y actúan las personas, ayudando a replicar la conducta humana.

Economía: Contribuye en la toma de decisiones, ya que una máquina debe pensar en beneficios, competidores y el balance entre ellos. Lingüística: Desde la lingüística, al conocer muy bien el idioma, se aportan bases fundamentales.

Lingüística computacional: Esta rama requiere un profundo conocimiento de las normas que rigen nuestra gramática.


- Chomsky fue el primero en establecer bases teóricas y computacionales de la lingüística, dejando una línea de trabajo clara sobre cómo representar el conocimiento, mostrar el lenguaje, sintetizar y estructurar.
- Por otro lado, enfrenta desafíos como las ambigüedades, especialmente difíciles de reconocer y resolver en el idioma español. Estas constituyen una de las principales dificultades del lenguaje.
Áreas principales de la IA
- Resolución de problemas.
- Representación del conocimiento (cómo se muestra la salida en pantalla).
- Búsquedas.
Áreas específicas
- Planificación de tareas (ej. scheduling para la organización de productos en contenedores).
- Procesamiento del lenguaje natural - NLP.
- Percepción.
- Razonamiento autónomo.
- Agentes autónomos.
- Sistemas basados en el Conocimiento.
- Aprendizaje Automático.
Problemas Reales para la IA
Algunos problemas reales que se pueden resolver mediante IA son:
- Diagnóstico Médico
- Mantenimiento Predictivo
- Gestión del Tráfico
- Detección de Fraude
- Análisis de Sentimientos
- Optimización de la cadena de suministro
- Servicio de atención al cliente
Algoritmos de redes como los usados en la gestión de tráfico y enrutamiento son ejemplos de la aplicación de la inteligencia artificial. Conocer y aplicar técnicas adecuadas es esencial.
Desde la computación podemos hablar de Hardware y herramientas para el desarrollo, ya que esta rama o área es la que más aporta a la IA.
Algunas limitaciones de la IA
¿Puede una computadora lidiar con la explosión combinatoria generada por muchos problemas?

¿Puede una máquina tener sentimientos?
Introducción a Python
Durante la asignatura, se utilizará Flask. Python es un lenguaje poderoso, interpretado y multiparadigma, con características como datos estructurados, no estructurados, diccionarios, y más. Por ejemplo, el uso de índices [:-2], diccionarios clave-valor (bases de NoSQL), y estructuras de procesamiento de lenguaje natural con listas anidadas. (Todos los temas importantes y relevantes se tendran en cuenta cuando llegue el momento de trabajarlos)
El uso de set y get en clases de Python, la sobrecarga de métodos (mismo nombre con diferentes parámetros) también son temas importantes que se cubrirán.
Se abordaran los temas desde cero de manera secuencial y ordenada.
Al ser una introducción se hablará sobre:
- Generalidades
- Python
- Flask
Concepto
Es un lenguaje de programación de tipo interpretado, multiparadigma. El lenguaje soporta orientación a objetos (POO), utiliza la programación imperativa y funcional, además es de tipado dinámico, multiplataforma y multipropósito.
Python es interpretado con un código legible mediante su interprete, el cual traduce y ejecuta. Es multiplataforma (Windows, Linux, Mac OS).

Algo especial del lenguaje es el Tipado Dinámico con sus mutaciones de variables, siendo fuertemente tipado, y sus tipos de variables.
Tipos de Datos
Encontramos en Python los tipos de datos Simples y Estructurados, comenzando con los simples tenemos:
- Números del tipo Entero o Flotante siempre y cuando no sean tan grandes para requerir el tipo Long
- Booleanos True o False (Verdadero o Falso)
Para los tipos de datos estructurados en Python:
- Secuencias: Listas, Tuplas, Strings, Unicode, Xrange, Range
- Mapeos: Diccionarios
- Conjuntos: set y frozenset
Entre otros como File, None, Notimplementedtype. Cabe resaltar que se requiere de una previa experiencia en cuanto a algoritmia y programación para entender los conceptos abordados.
A partir de este punto vendrán una serie de ejemplos de código Python (Altamente recomendado probarlos en la máquina y ejecutarlos para practicar, sobre todo entender que hacen los códigos).
Python - Programación Estructurada
Variables 1
cadena = "Hola Muchachos"
entero = 18
flotante = 18.1
booleana = True
print(cadena)
print(entero)
print(flotante)
print(booleana)
#TYPE MUESTRA EL TIPO DE DATO (Consola).
type(cadena)
print(type(cadena))
Listas 1
objetos = ["Casa", "Vehiculo", "Ventana"]
numeros = [111, 222, 333, 444, 555, 666]
numeros2 = [3, 5 ,7]
objetos.append('Pablo') # AGREGAR ELEMENTO
objetos.extend('Maria') # AGREGAR ['M', 'a', 'r', 'i', 'a']
numeros.extend(numeros2) # AGREGAR LISTA A OTRA
objetos.insert(2, 'Camilo') # INSERTAR EN UNA POSICIÓN ESPECÍFICA
objetos.pop(2) # ELIMINAR ELEMENTOS EN UNA POS. ESPECÍFICA. DEFAULT, EL ÚLTIMO
objetos.remove('Vehiculo') # REMOVER INDICANDO EL ELEMENTO, SIN ÍNDICE
# RANGE
a = list(range(10)) # GENERA NÚMEROS DE 0 A 9
b = list(range(2, 20, 2)) # GENERA NÚMEROS DE 2 HASTA 20 DE 2 EN 2
print(b)
Listas 2
# CREAR LISTA POR EXTENSIÓN
a = [0, 2, 4, 6, 8]
print(a)
# CREAR POR COMPRENSIÓN
a = [x for x in range(9) if x % 2 == 0]
print(a)
Tuplas 1
things = ('casa', 'puerta', 'reloj', 'mesa', 'silla', 'banco', 'cuadro', 'alfombra')
numbers = (1, 2, 3, 4, 5, 6)
print(numbers[0:3]) # MUESTRA (1, 2, 3), DESDE LA POS 0 HASTA LA ULTIMA INDICADA DESPUES DEL : -1, DEL 0 HASTA EL 3-1 IMPRIME EL LA POS: 0,1,2 OSEA (1,2,3)
print(numbers[:-2]) # MUESTRA (1, 2, 3) SIN LOS ÚLTIMOS 3 DIGITOS
Diferencias entre Listas y Tuplas
| Listas | Tuplas |
| Son Dinámicas | Son Estáticas |
| Utilizamos Corchetes [] | Utilizamos Paréntesis () |
| Elementos separados por coma | Elementos separados por coma |
| List = [1, 2] | Tuple = (1, 2) |
| Acceso a elementos por [Índice] | Acceso a elementos por [Índice] |
Diccionarios - Estructura
| Clave | Key |
| Nombre | Margarita |
| Edad | 23 |
| Genero | Femenino |
Diccionarios 1
# DECLARACIÓN
miDiccionario = {
'Nombre' : 'Mario',
'Edad' : '25',
'Genero' : 'Masculino'
}
# ACCEDER A UN DICCIONARIO
persona = {
'Nombre' : 'MANUEL',
'Apellido' : 'ARIAS',
'Padres' : ['MARIO ARIAS', 'CATALINA ROJAS'],
'Edad' : 24,
'Genero' : 'MASCULINO',
'Estado Civil' : 'CASADO',
'Hijos' : 'NO REGISTRA',
'Mascotas' : 'GATOS',
'Nombres de mascotas' : 'COPITO'
}
Diccionarios 2
print(persona['Apellido']) # ACCEDER AL APELLIDO
print(persona['Padres']) # ACCEDER A LA LISTA DE PADRES
persona['Ingresos'] = '1600000' # AGREGAR CAMPOS
persona['Ingresos'] = '2200000' # AGREGAR CAMPOS. SI EXISTE CAMBIA EL VALOR
persona['Salario'] = persona.pop('Ingresos') # CAMBIAR INGRESOS POR SALARIOS
del(persona['Nombre']) # BORRAR EL CAMPO NOMBRE DEL DICCIONARIO
objeto = persona.get('Nombre', 'N.A') # OBTENER EL NOMBRE. SI ENCUENTRA IMPRIME N.A
claves = persona.keys() # IMPRIME TODAS LAS CLAVES
valores = persona.values() # IMPRIME LOS VALORES
Condicionales 1
# IF / ELSE
a = 2 + 3
if a == 4:
print('A ES IGUAL A CUATRO') # IMPRIMIR
else:
print('NO SE CUMPLE LA CONDICIÓN')
# IF / ELIF / ELSE
a = 2 + 3
if a == 4:
print('A ES IGUAL A CUATRO')
elif a == 5:
print('A ES IGUAL A CINCO')
elif a == 6:
print('A ES IGUAL A SEIS')
else:
print('NO SE CUMPLE LA CONDICIÓN')
Condicionales 2
# EJEMPLO
dinero = 50000
if (dinero >= 25000):
print('HAS COMPRADO UN LIBRO')
dinero = dinero - 25000
print(('TU SALDO ES:'), (dinero))
else:
print('USTED NO TIENE DINERO NECESARIO!!')
Lista de operadores Aritméticos
| Operador | Función | Ejemplos |
| + | Sumar | 2 + 2 |
| - | Restar | 3 - 2 |
| * | Multiplicar | 2 * 2 |
| / | Dividir | 4 / 2 |
| % | Módulo | 4 % 2 |
| ** | Exponente | 3 ** 2 |
| // | División Entera | 8 // 4 |
Lista de operadores Especiales
| Operador | Función | Ejemplos | Resultado |
| In | El operador In devuelve True si un elemento se encuentra dentro de otro | a = [3,4] 3 in a | True Porque 3 se encuentra en a |
| Not in | El operador Not In devuelve True si un elemento no se encuentra dentro de otro | a = [3,4] 5 in a | True Porque 5 no se encuentra en a |
| Is | El operador Is devuelve True si los elementos son exactamente iguales | x = 10, y = 10, x is y | True Porque ambas variables tienen 10 |
| Not Is | El operador Not Is devuelve True si los elementos no son exactamente iguales | x = 10, y = 111, x not is y | True Porque estas variables no tienen el mismo valor |
Operadores 1
# OPERADORES ARITMÉTICOS
print((12), ('+'), (14))
print(('resultado1:'), (12 + 14))
a = 12
b = 145
print((a), ('+'), (b))
print(('resultado2:'), (a + b))
# COMPARACIÓN
dinero = 100000
if (dinero >= 25000):
print('HAS COMPRADO UN LIBRO')
dinero = dinero - 25
print(('TU SALDO ES:'), (dinero))
else:
print('USTED NO TIENE DINERO')
Operadores 2
# ASIGNACIÓN
year = 1993
month = 10
current_year = 2024
current_month = 1
if current_year == 2024 and current_month < year:
edad = current_year - year
print(('LA EDAD ES:'), (edad))
if current_year == 2024 and current_month > month:
edad = current_years - years
edad += 1
print(('LA EDAD ES:'), (edad), ('NACIO EN MES '), (month), ('Y ES MES'), (current_month))
# LÓGICOS
edad_minH = 21
edad_minM = 18
pablo_edad = 23
mario_edad = 18
sofia_edad = 29
# COMPROBAMOS SI LOS 3 CUMPLEN LA EDAD MÍNIMA
if pablo_edad > edad_minH and mario_edad > edad_minH and sofia_edad > edad_minM:
print('LOS TRES CUMPLEN')
# COMPROBAMOS SI ALGUNO NO LA CUMPLE
if pablo_edad < edad_minH or mario_edad < edad_minH or sofia_edad < edad_minM:
print('ALGUNO NO CUMPLE')
# ESPECIALES
lista_invitados = ['Angelica', 'Matias', 'Sofia', 'Juan', 'Antonio', 'Marcelo', 'Diana', 'Ruben']
x = 'Andres'
if x in lista_invitados:
print('SI ESTA EN LA LISTA')
else:
print('NO SE ENCONTRO')
Funciones de Cadenas 1
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| print() para imprimir todo | Imprime en pantalla el argumento | print(‘Hola’) | Hola |
| len() | Determina la longitud en caracteres de una cadena | len(‘HOLA’) | 4 |
| join() | Convierte en cadena utilizando una separación | Lista = [‘Python’,’es’] ‘-‘.join(Lista) | ‘Python-es’ |
| split() | Convierte una cadena con un separador en una lista | a = (‘HOLA’) Lista2 = a.split() print(Lista2) | HOLA |
Funciones de Cadenas 2
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| replace() en strings | Remplaza una cadena por otra | texto = ‘Manuel es mi amigo’ print(texto.replace(‘es’,’era’)) | Manuel era mi amigo |
| upper() | Convierte una cadena en Mayúscula | texto = ‘Manuel es mi amigo’ texto.upper() | MANUEL ES MI AMIGO |
| lower() | Convierte una cadena en Minúscula | texto = ‘MANUEL ES MI AMIGO’ texto.lower() | manuel es mi amigo |
Funciones Numéricas 1
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| range() para iterables | Crea un rango de números, se usa para crear listas o para iterables | x = range(5) | [0, 1, 2, 3, 4] |
| str() | Convierte un valor numérico a texto | str(22) | ‘22’ |
| int() | Convierte a valor entero | int(‘22’) | 22 |
| float() | Convierte un valor a decimal | float(‘2.22’) | 2.22 |
Funciones Numéricas 2
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| max() para números | Determina el máximo entre un grupo de números | x = [0, 1, 2] print(max(x)) |
2 |
| min() | Determina el mínimo entre un grupo de números | x = [0, 1, 2] print(min(x)) |
0 |
| sum() | Suma el total de una lista de números | x = [0, 1, 2] print(sum(x)) |
3 |
Funciones Útiles 1
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| all() | Verifica si todos los elementos de un iterable son verdaderos | all([True, True, False]) |
False |
| any() | Verifica si algún elemento de un iterable es verdadero | any([False, False, True]) |
True |
| zip() | Combina iterables en tuplas | list(zip([1, 2], ['a', 'b'])) |
[(1, 'a'), (2, 'b')] |
| map() | Aplica una función a cada elemento de un iterable | list(map(str.upper, ['hola', 'mundo'])) |
['HOLA', 'MUNDO'] |
| filter() | Filtra elementos de un iterable usando una función | list(filter(lambda x: x > 0, [-1, 2, -3, 4])) |
[2, 4] |
| enumerate() | Devuelve elementos y sus índices | list(enumerate(['a', 'b', 'c'])) |
[(0, 'a'), (1, 'b'), (2, 'c')] |
| reversed() | Invierte un iterable | list(reversed([1, 2, 3])) |
[3, 2, 1] |
| isinstance() | Comprueba si un objeto es de un tipo específico | isinstance(5, int) |
True |
| getattr() | Obtiene un atributo de un objeto | getattr(obj, 'nombre', 'default') |
Valor del atributo o 'default' |
| setattr() | Establece un atributo en un objeto | setattr(obj, 'nombre', 'valor') |
Atributo actualizado |
| delattr() | Elimina un atributo de un objeto | delattr(obj, 'nombre') |
Atributo eliminado |
| eval() | Evalúa una expresión como código | eval('2 + 2') |
4 |
| exec() | Ejecuta un bloque de código | exec("x = 5; print(x)") |
5 |
| vars() | Devuelve un diccionario de atributos de un objeto | vars(obj) |
Diccionario de atributos |
| import() | Importa un módulo en tiempo de ejecución | mod = __import__('math') |
Módulo importado |
Funciones Útiles 2
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| abs() | Devuelve el valor absoluto de un número | abs(-10) |
10 |
| round() | Redondea un número al entero más cercano o a decimales | round(3.14159, 2) |
3.14 |
| sorted() | Devuelve una lista ordenada de un iterable | sorted([3, 1, 2]) |
[1, 2, 3] |
| frozenset() | Crea un conjunto inmutable | frozenset([1, 2, 3]) |
frozenset({1, 2, 3}) |
| chr() | Devuelve el carácter Unicode para un código dado | chr(65) |
'A' |
| ord() | Devuelve el código Unicode para un carácter dado | ord('A') |
65 |
| bin() | Convierte un número a su representación binaria | bin(10) |
'0b1010' |
| hex() | Convierte un número a su representación hexadecimal | hex(255) |
'0xff' |
| oct() | Convierte un número a su representación octal | oct(8) |
'0o10' |
| next() | Obtiene el siguiente elemento de un iterador | it = iter([1, 2]); next(it) |
1 |
| pow() | Calcula la potencia de un número | pow(2, 3) |
8 |
| sum() | Suma los elementos de un iterable | sum([1, 2, 3]) |
6 |
| hasattr() | Verifica si un objeto tiene un atributo | hasattr(obj, 'nombre') |
True o False |
| callable() | Verifica si un objeto es llamable como función | callable(print) |
True |
Funciones Especiales 1
| Función | Utilidad | Ejemplo | Resultado |
|---|---|---|---|
| compile() | Compila una cadena en un objeto de código ejecutable | code = compile('x = 5', '<string>', 'exec') |
Objeto compilado |
| eval() | Evalúa una expresión como código | eval('2 + 2') |
4 |
| complex() | Crea un número complejo | complex(1, 2) |
(1+2j) |
| globals() | Devuelve un diccionario de variables globales | globals() |
Diccionario de variables globales |
| locals() | Devuelve un diccionario de variables locales | locals() |
Diccionario de variables locales |
| memoryview() | Crea un objeto de vista de memoria de un objeto de bytes | memoryview(b'abc') |
Vista de memoria |
| super() | Devuelve una referencia al padre de una clase | super().metodo() |
Referencia al método del padre |
| slice() | Crea un objeto de segmento | slice(1, 5) |
Segmento |
| property() | Crea y administra propiedades | property(fget, fset) |
Objeto propiedad |
| type() | Devuelve el tipo de un objeto o crea una nueva clase | type(5) |
<class 'int'> |
Funciones Propias 1
# FUNCIONES
def sumar(a, b):
x = a + b
print(('Resultado'), (x))
sumar(5, 7) ## LLAMAR LA FUNCIÓN
#################################
def func(param1, param2):
res = param1 ** param2
return res
variable = func(8, 2)
print(variable)
Funciones Propias 2
def sumar():
x = a + b
print(('Resultado:'), (x))
def restar():
x = a - b
print(('Resultado:'), (x))
def multiplicar():
x = a * b
print(('Resultado:'), (x))
def dividir():
x = a / b
print(('Resultado:'), (x))
while True:
try:
a = int(input('INGRESE EL PRIMER NÚMERO: \n'))
b = int(input('INGRESE EL SEGUNDO NÚMERO: \n'))
print(('QUÉ CALCULO ENTRE'), (a), ('Y'), (b), ('?\n'))
op = str(input("""
1- Sumar
2- Restar
3- Multiplicar
4- Dividir \n"""
))
except: # EN CASO DE ERROR
print('ERROR')
op = '?'
if op == '1':
sumar()
break
elif op == '2':
restar()
break
elif op == '3':
multiplicar()
break
elif op == '4':
dividir()
break
else:
print('NÚMERO NO VALIDO')
Ciclos 1
# CICLO FOR
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
for num in numeros:
if num % 2 != 0:
print(num)
# ITERAR LISTAS
palabras = ['CARRO', 'CELULAR', 'TV', 'NEVERA', 'MÉDICO', 'ESCRITORIO', 'VENTILADOR']
for caracteres in palabras:
print((caracteres), ('---->LONGITUD:'), (len(caracteres)))
Ciclos 2
# ITERAR DICCIONARIOS
agenda = {
'MARIA' : '25899999',
'PABLO' : '3443456992',
'JOSE' : '1596358',
'ANGELA' : '789657',
'CARLOS' : '75698788'
}
for (k, v) in agenda.items():
print(k, v)
# ITERAR STRINGS
entrada = "HOLA ESTAMOS EMPEZANDO SEMESTRE"
contador = 0
cuentaletra = 'E'
for letra in entrada:
if letra == cuentaletra:
contador = contador + 1
print(('CANTIDAD DE LETRAS'), (cuentaletra), (':'), (contador))
Ciclos 3
# CICLO WHILE
i = 0
while (i <= 9):
i += 1
print(i)
# CICLO INFINITO
while True:
opcion = (input("""ELIJA UNA FRUTA:
1- NARANJA
2- MANDARINA
3- NINGUNA
""")
if opcion == '1':
print('SELECCIONÓ NARANJAS')
break
elif opcion == '2':
print('SELECCIONÓ MANDARINA')
break
elif opcion == '3':
print('SELECCIONÓ NINGUNA')
break
else:
print('DEBE SELECCIONAR UNA OPCION (1, 2 o 3)')
Ciclos 4
# CONTINUE
cadena = 'python3'
for letra in cadena:
if letra == '3':
continue
print(letra)
# PASS
for num in range(10):
if num == 8:
pass
print(f'EL NÚMERO ACTUAL ES: {num}')
print('LA CUENTA HA TERMINADO')
counter = 0
while counter < 5:
print(f'EL NÚMERO {counter} ES INFERIOR A 5')
counter = counter + 1
else:
pass
Excepciones 1
def sumar():
x = a + b
print(('Resultado:'), (x))
def restar():
x = a - b
print(('Resultado:'), (x))
def multiplicar():
x = a * b
print(('Resultado:'), (x))
def dividir():
x = a / b
print(('Resultado:'), (x))
while True:
try:
a = int(input('INGRESE EL PRIMER NÚMERO: \n'))
b = int(input('INGRESE EL SEGUNDO NÚMERO: \n'))
print(('QUÉ CALCULO ENTRE'), (a), ('Y'), (b), ('?\n'))
op = str(input("""
1- Sumar
2- Restar
3- Multiplicar
4- Dividir \n"""
))
if op == '1':
sumar()
break
elif op == '2':
restar()
break
elif op == '3':
multiplicar()
break
elif op == '4':
dividir()
break
else:
print('NÚMERO NO VALIDO')
except ZeroDivisionError:
print('NO SE PERMITE LA DIVISIÓN ENTRE CERO. ERROR')
except:
print('ERROR EN EL PROGRAMA')
finally:
print('GRACIAS POR UTILIZAR EL PROGRAMA CALCULADORA')
####
#Name error
while True:
print(a)
Excepciones 2
###
#Typer error
a = 12
b = 'Hola'
print(a + b) # no se puede sumar 12 + hola
#################
#Aserciones - ESPECIFICAR INVARIANTES
dinero = -19
if dinero >= 12:
print(("TIENES"), (dinero), ("MONEDAS, ES MAYOR A 12"))
elif dinero <= 12:
print(("TIENES"), (dinero), ("MONEDAS, ES MENOR A 12, INSUFICIENTE"))
assert dinero > 0, "ERROR AL COMPROBAR, VALOR NEGATIVO"
Archivos 1
Archivos 2
Iterables por comprensión
Diccionarios por compresión
Format y Join
Python - Programación Orientada a objetos
Clases, métodos y objetos 1
Clases, métodos y objetos 2
Herencia Multiple 1
Herencia Multiple 2
Herencia Multiple 3
Super 1
Super 2
Super 3
Super 4
Super 5
Super 6
Super 7
Variables de Clase e Instancia 1
Variables de Clase e Instancia 2
Variables de Clase e Instancia 3
Variables de Clase e Instancia 4
Decoradores 1
Decoradores 2
Decoradores 3
Decoradores 4
Atributos 1
Atributos 2
Atributos 3
Atributos 4
Polimorfismo y sobrecarga 1
Polimorfismo y sobrecarga 2
Polimorfismo y sobrecarga 3
Módulo 1
Modularidad 1
Python - Ejercicio Menú
Menú 1
Menú 2
Menú 3
Menú 4
Menú 5
Flask - Instalación
Ejemplos
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
Bases NLP
El conocimiento del lenguaje y sus estructuras es esencial para trabajar con PLN:
- S: Oración principal.
- SN: Sintagma nominal (grupo de palabras que cumplen la función de sujeto).
- SV: Sintagma verbal (grupo de palabras que contiene el verbo y el complemento).
- SAdj: Sintagma adjetival (grupo de palabras cuyo núcleo es un adjetivo).
- SAdv: Sintagma adverbial (grupo de palabras cuyo núcleo es un adverbio).
- SPrep: Sintagma preposicional (grupo de palabras que comienzan con una preposición).
Los elementos clave en una oración son el sujeto (quien realiza la acción), el predicado (la acción realizada por el sujeto), y el complemento (directo, indirecto, circunstancial).
Clases de palabras
- N: Sustantivo.
- V: Verbo.
- Adj: Adjetivo.
- Adv: Adverbio.
- Det: Determinante.
- Prep: Preposición.
- Conj: Conjunción.
Durante el curso se trabajarán las bibliotecas NLTK y Spacy, dividiendo las frases según la función de cada palabra.
NLP - Pipeline
Un pipeline de NLP es una serie de pasos que permiten procesar texto de manera estructurada. Estos pasos incluyen la adquisición de datos, limpieza, preprocesamiento, extracción de características, modelado, evaluación y despliegue.
Los pasos más comunes incluyen:
- Tokenización: Dividir el texto en palabras o frases.
- Limpieza: Eliminar mayúsculas/minúsculas, dígitos, signos de puntuación, y normalizar el texto.
- POS Tagging: Etiquetado de las palabras según su función gramatical.
- Stop Words: Eliminar palabras irrelevantes como artículos y preposiciones.
- Ingeniería de características: Detectar elementos relevantes del texto y extraer características importantes.
Un pipeline podría verse así: tokenización → POS tagging → eliminación de stop words → extracción de características → modelado con machine learning.
El proceso más extenso de un pipeline es la ingeniería de características, que permite dar mayor sentido al texto y extraer información relevante.
Finalmente, la evaluación de modelos se realiza mediante métricas como la precisión (precision), el recuerdo (recall), y el tiempo de respuesta.
Text Representation
Es necesario representar el texto de alguna manera. Tradicionalmente, se realizaba un preprocesamiento, separando párrafos y palabras, pero no es tan sencillo. Estas son las formas más comunes que tenemos para representar los textos en vectores.
Existen varias técnicas, y veremos las más conocidas. Los modelos de deep learning utilizan redes neuronales para realizar ingeniería de características o para tratar con el lenguaje.
La representación de texto hace referencia a la transformación de texto escrito en una representación numérica. El objetivo es convertir un texto determinado en forma numérica para que pueda incorporarse a los algoritmos de PLN (Procesamiento de Lenguaje Natural) y Machine Learning.
Pipeline para la Representación de Texto
Para la representación de texto, existen varias tareas:
- Texto crudo
- Limpieza y preprocesamiento
- Tokenización
- Representación matemática en vectores
El preprocesamiento no siempre es visible, pero es esencial para evaluar el modelo.
Extracción del Significado en las Oraciones
Es fundamental encontrar el sentido de las oraciones, ya que el contexto juega un papel crucial en la comprensión del texto. Es necesario saber en qué lugar está ubicada una palabra para entender de qué se está hablando. Algunos pasos importantes son:
- Dividir en unidades léxicas las palabras (lexemas).
- Deducir el significado.
- Comprender la estructura semántica.
- Comprender el contexto en el que aparece la frase.
Enfoques para la Clasificación de Texto
Existen diversos enfoques válidos para la representación de texto en modelos de Machine Learning, y se pueden crear reglas para refinar el modelo.
Modelos de Espacio Vectorial
Similitud del coseno: Se utiliza para medir la similitud entre dos frases basándose en el ángulo que forman sus vectores. Distancia euclidiana: La distancia cuadrada entre palabras se mide utilizando matrices y determinantes para evaluar su similitud.
Enfoques de Vectorización
El primer paso es hablar de un corpus, una serie de documentos con un vocabulario. El corpus puede ser un PDF completo, una frase, etc., y se genera un vocabulario a partir de él. Algunos enfoques comunes incluyen:
- One-Hot Encoding: Se crea una matriz donde cada palabra es representada como un vector, y la frase se representa con una lista de vectores.
- Bag of Words: Es un enfoque muy utilizado donde, en lugar de una matriz, se crea una lista en la que cada palabra está encendida (1) o apagada (0).
- Bag of N-Grams: Permite crear N-gramas para buscar en los corpus, logrando entender frases completas.
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF es una técnica ampliamente usada en NLP. Aplica una fórmula que combina la frecuencia de término con la frecuencia inversa de documentos, multiplicando ambos valores para obtener una representación ponderada del texto.
Similitud Distributiva y Representación Distributiva
Otros conceptos relevantes incluyen:
- Connotación: El significado según el contexto de la palabra.
- Denotación: El significado literal de la palabra.
- Hipótesis Distributiva: En lingüística, esta hipótesis sugiere que las palabras que ocurren en contextos similares tienen significados similares. Por ejemplo: “perro” y “gato”.
La representación distributiva se refiere a la distribución de las palabras en el contexto en el que aparecen, utilizando vectores y matrices.
Embeddings
Un embedding es una representación numérica de un conjunto de palabras en un corpus.
Word2Vec: Esta técnica entrena un sistema con redes neuronales para relacionar palabras. Básicamente, toma una palabra, la combina con otras y crea una nueva palabra basada en relaciones semánticas. El objetivo es capturar las relaciones entre las palabras para entender mejor el texto.
Continuous Bag of Words (CBOW): Este modelo busca encontrar la palabra central en una frase que proporciona el contexto de lo que está a su alrededor, midiendo la distancia semántica.
Representación Universal
La representación universal intenta generalizar las palabras para visualizar su significado en diferentes contextos.
Esfuerzo y Retorno
En el desarrollo de aplicaciones como chatbots o sistemas de procesamiento de lenguaje, es necesario invertir esfuerzo. El retorno depende de si hay una necesidad comercial o si la implementación cumple con los objetivos planteados.
Limitaciones de Infraestructura
Es importante considerar las limitaciones de la infraestructura al implementar estos modelos, ya que pueden requerir grandes cantidades de recursos computacionales.
Referencias
Esta publicación ha sido creada como soporte en mi formación académica y crecimiento profesional.
© Juan David Garcia Acevedo (aka liandd)